nt-string: The missing Windows string types for Rust

This release was not planned. I actually wanted to write a parser for Windows apiset DLLs, but quickly found myself implementing the umpteenth string type to handle Windows UTF-16 characters. After having done that work once for nt-hive and another time for ntfs, it was time to refactor the common parts into a crate and make it usable in a wider context.
A quick research revealed the widestring crate, which already did 60% of what I wanted. Shoutout to Kathryn Long at this point for the excellent work!
However, I was still missing two important parts:
The
UNICODE_STRINGtype, which has been widely used by the Windows kernel team and also spilled over to some user-mode APIs.A type to work with serialized UTF-16 Little-Endian strings, requiring no allocations or prior conversions to other string types. With UTF-16 being the omnipresent character encoding in Windows, my ntfs crate already needed that, and my upcoming nt-apiset crate will as well.
What is a UNICODE_STRING?
The UNICODE_STRING type was designed for the C programming language, which only knows about NUL-terminated buffers of characters.
To determine the length of such a buffer, you need to iterate over all characters until finding the NUL.
Bad enough?
It gets worse:
A classic buffer overflow occurs if the buffer contains no NUL, but an algorithm attempts to find it anyway.
To overcome these performance and security hazards, UNICODE_STRINGs consist of a buffer, a buffer capacity (“maximum length”), and a field to indicate the actually used length:
typedef struct _UNICODE_STRING
{
USHORT Length;
USHORT MaximumLength;
PWSTR Buffer;
}
UNICODE_STRING, *PUNICODE_STRING;
Determining length and capacity is now as simple as querying the corresponding fields.
This crate makes UNICODE_STRING a first-class Rust citizen.
You get 3 Rust types to handle references (NtUnicodeStr), mutable references (NtUnicodeStrMut), and owned strings (NtUnicodeString), which look and feel just like Rust’s standard &str, &mut str, and String types.
All my implemented methods are fallible and supposed to never panic.
The only exception are allocations and traits like Add, where Rust currently does not provide fallible alternatives.
To NUL or not to NUL?
During my years in the Windows developer community, I discovered several string types where the terminating NUL character is optional.
One example are strings in compiled program resources, and UNICODE_STRING is another such example.
However, this didn’t stop the broader developer community from treating these types as NUL-terminated strings.
If their empirical tests on 1 or 2 strings showed that they end with a NUL terminator, they were simply handled like regular C strings from now on.
And unless you bothered to read the documentation, the Buffer field of UNICODE_STRING with its PWSTR type looks exactly like any other C wide-string.
The C type definition cannot express whether a string is NUL-terminated or not.
My Rust implementation of UNICODE_STRING wouldn’t need to care about that.
When exposing the string to the user, it always takes the length field into account and doesn’t consider NUL terminators.
The internal buffer is hidden from the user to prevent any incorrect usage.
But what happens when we’re interfacing with the C world?
Your UNICODE_STRING will most likely be passed to C code at some point, or you hardly had a reason to use UNICODE_STRING at all.
I wanted to be on the safe side here.
Whenever possible, my implementation of UNICODE_STRING allocates one more byte to NUL-terminate its internal buffer.
No matter if your C application knows how to handle UNICODE_STRINGs or if it mistakenly treats it as a C string, you will be fine either way.
Examples
Enough said, let’s have some code to show you that these string types work just like any other string types in Rust:
let mut string = NtUnicodeString::try_from("Hello! ")?;
string.try_push_str("Moin!")?;
println!("{string}");
Conversions are also supported from raw u16 string buffers as well as the U16CStr and U16Str types of the widestring crate:
let abc = NtUnicodeString::try_from_u16(&[b'A' as u16, b'B' as u16, b'C' as u16])?;
let de = NtUnicodeString::try_from_u16_until_nul(&[b'D' as u16, b'E' as u16, 0])?;
let fgh = NtUnicodeString::try_from(u16cstr!("FGH"))?;
let ijk = NtUnicodeString::try_from(u16str!("IJK"))?;
Constant UNICODE_STRINGs can be created at compile-time.
This provides strings with a 'static lifetime and saves a UTF-16 conversion at runtime:
const MY_CONSTANT_STRING: NtUnicodeStr<'static> = nt_unicode_str!("Hi!");
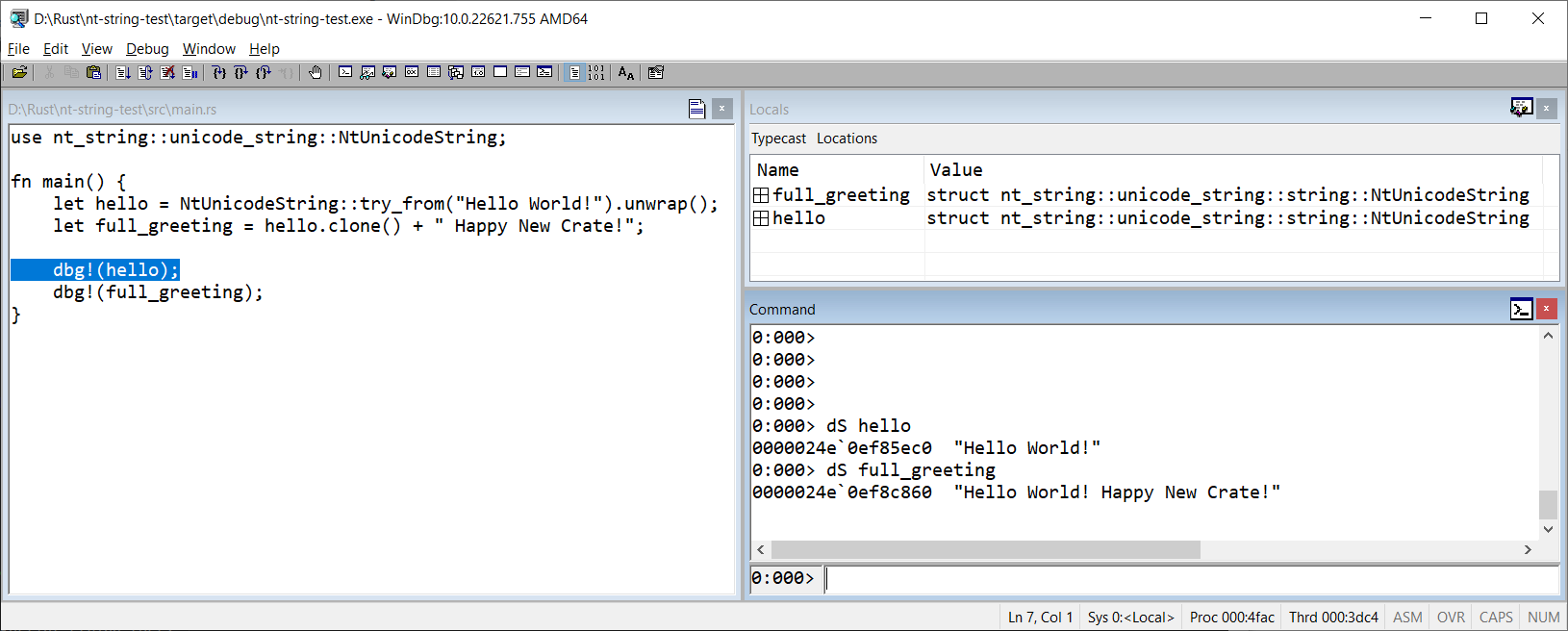
Demo
A picture says more than a thousand words, so here is the obligatory WinDbg screenshot that confirms the compatibility of my implementation with the original UNICODE_STRING:
And what about the other type?
I promised two types with this crate, and the other one is in no way less important.
U16StrLe takes a byte buffer and interprets it as UTF-16 codepoints stored in little-endian byte order.
I chose this name because it nicely fits with the U16CStr and U16Str types of the widestring crate.
Even though you will often convert a U16StrLe to another string type, it serves two purposes:
Parsing a byte buffer containing a serialized UTF-16 string, and returning that string without an allocation.
I do this a lot in ntfs, I will need it again in my apiset DLL parser, and I can imagine lots of other scenarios.Comparing, checking for equality, and printing such strings.
No need for a conversion here, this can be done directly and without allocations.
Conclusion
I hope you find my new crate as useful as I do. Feedback is always welcome and my contact details are in the upper right corner.